order by工作原理
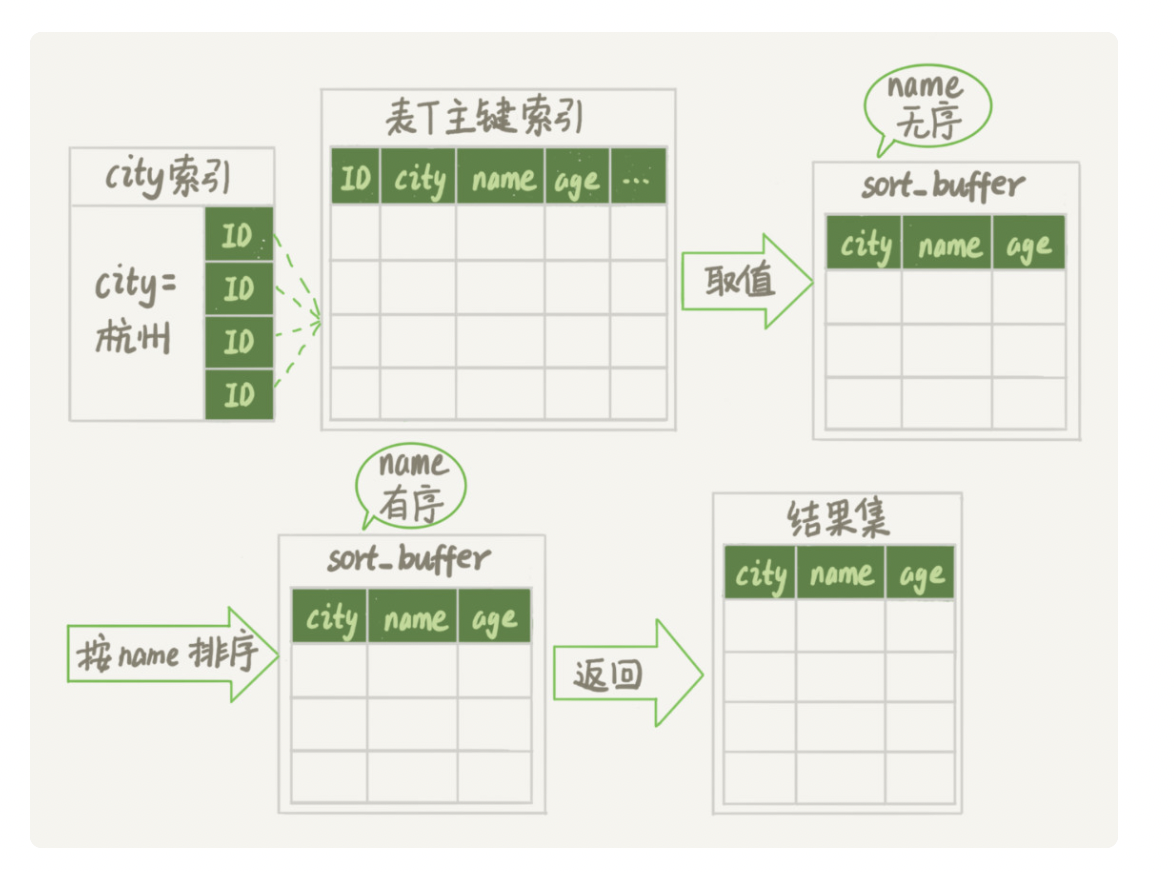
全字段排序
MySQL会给每个线程分配一块内存用于排序,称为sort buffer。
1.初始化 sort_buffer,确定放入 name、city、age 这三个字段;
2.从索引 city 找到第一个满足 city=’杭州’条件的主键 id,也就是图中的 ID_X;
3.到主键 id 索引取出整行,取 name、city、age 三个字段的值,存入 sort_buffer 中;
4.从索引 city 取下一个记录的主键 id;
5.重复步骤 3、4 直到 city 的值不满足查询条件为止,对应的主键 id 也就是图中的 ID_Y;
6.对 sort_buffer 中的数据按照字段 name 做快速排序;
7.按照排序结果取前 1000 行返回给客户端。
sort_buffer_size ,就是MySQL为排序开辟的内存(sort_buffer)的大小。如果要排序的数据量小于sort_buffer_size,排序就在内存中完成。如果数据量太大,内存放不下,则不得不利用磁盘临时文件辅助排序。
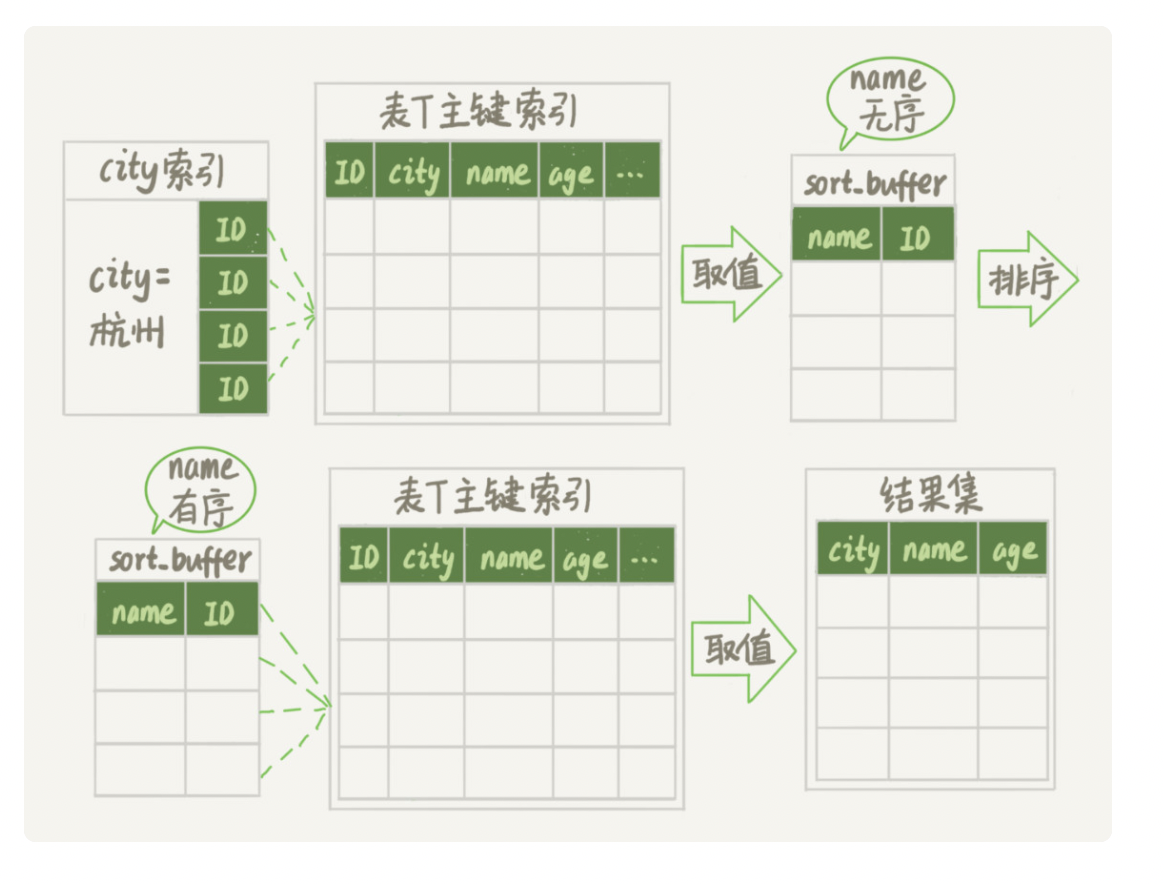
rowid排序
如果sort_buffer里面要存放的字段数太多,这样内存能存的行数很少,要分成很多个临时文件,排序性能会很差。可以通过修改max_length_for_sort_data的值来改变排序算法。
1.初始化 sort_buffer,确定放入两个字段,即 name 和 id;
2.从索引 city 找到第一个满足 city=’杭州’条件的主键 id,也就是图中的 ID_X;
3.到主键 id 索引取出整行,取 name、id 这两个字段,存入 sort_buffer 中;
4.从索引 city 取下一个记录的主键 id;
5.重复步骤 3、4 直到不满足 city=’杭州’条件为止,也就是图中的 ID_Y;
6.对 sort_buffer 中的数据按照字段 name 进行排序;
7.遍历排序结果,取前 1000 行,并按照 id 的值回到原表中取出 city、name 和 age 三个字段返回给客户端。
全字段排序 VS Rowid排序
由于Rowid排序涉及到回表,如果内存足够,就优先使用内存,即全字段排序。
优化手段:可以使用覆盖索引,索引上的信息足够满足查询请求,不需要再回主键索引上去取数据。