后台服务出现明显“变慢”
具体步骤
1.检查应用本身的错误日志。
2.可以检查系统级别的资源占用情况,例如CPU、内存是否被其他进程大量占用。
3.监控Java 服务自身,例如GC 日志里面是否观察到FULL GC等恶劣情况,或者其他进程大量占用,并且这种占用是否不符合系统的正常运行情况。
4.如果不能定位具体问题,对应用进行Profing也是个办法,但会影响系统的响应速度。
5.定位错误后,采取相应的不久措施。
性能分析
1.自上而下。从应用的顶层,逐步深入到具体的不同模块。
2.自下而上。从类似CPU这种硬件底层,判断Cache-Miss之类的问题和调优机会,出发点是指令级别优化。
自上而下(单机应用)
系统性能分析中,CPU、内存和IO是主要关注项。
CPU排查
查看负载有没有明显的变化,利用top和jstack 找出最耗费CPU的线程。利用vmstat,查看上下文切换的数量,
如果每秒上下文切换很高,并且比系统中断高很多,就表明有可能是因为不合理的多线程调度导致的。
内存排查
利用free 之类查看内存使用,进一步判断swap使用情况,top命令输出中Virt作为虚拟内存使用量,就是物理内存(Res)和swap 求和。
IO排查
利用iostat等命令判断磁盘的健康情况。
JVM 层面的性能分析
1.利用JMC、JConsole等工具进行运行时监控。
2.利用各种工具,在运行时进行堆转存储分析,获取各种角度的统计数据。
3.GC 日志等手段,诊断 Full GC 、Minor GC、或者引用堆积。
4.应用Profiling,来实现从Hotspot JVM内部收集底层信息,通常会有2%左右的损耗。
Lambda让程序“慢30倍”?
一般来说,可以认为Lambda/Stream 提供了与传统方式接近对等的性能。主要的开销:初始化的开销。
Lambda并不是语法糖,而是一种新的工作机制。在首次调用时,JVM需要为其构建。如果 Java 应用启动过程中引入很多Lambda语句,会导致启动过程变慢。
通过引入基准测试,可以定义性能对比的明确条件、具体的指标,进而保证得到定量的、可重复的对比数据,这是工程中的实际需要。
微基准测试
当需要对一个大型软件的某小部分的性能评估时,就可以考虑微基准测试。
微基准测试通常是API级别的验证,一般是偏基础、底层平台开发者的需求。(通常使用Benchmark)。
微基准框架
目前最为广泛的框架之一就是 JMH。如果做 Java API级别的性能对比,JMH往往是首选。
微基准框架测试过程的闭坑
1.保证代码经过了足够并且合适的预热。JVM会对代码进行优化,JIT会一定条件下将代码编译本地代码。
2.防止 JVM 进行无效代码消除,尽量保证方法有返回值,而不是void方法。
3.防止发生常量折叠。JVM 如果发现计算过程依赖常量,就可能会直接计算结果。JMH提供了State机制来解决这个问题。
4.避免GC 对程序的影响,可以采用 Serial GC 或者 JDK 11引入的Epsilon GC,从而排除相关的影响。
JVM优化代码
JVM 在对代码执行的优化可分为运行时优化(runtime)和即时编译器(JIT)优化。
运行时优化
主要是解释执行和动态编译通用的一些机制,比如锁机制、内存分配机制(如TLAB)等。还有一些专门用于优化解释执行效率的,比如说模版解释器、内联缓存等。
即时编译器优化
指将热点的代码以方法为单位转换成机器码,直接运行在底层硬件之上。比如静态编译器可以使用方法内联、逃逸分析以及基于profile的投机性优化。
Java优化的落地
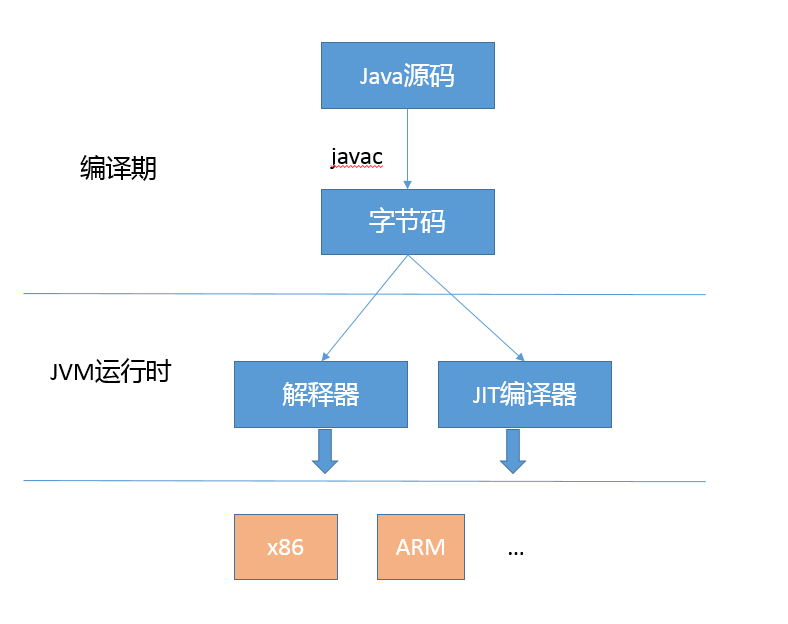
编译期:编译器或者相关API等奖源码转换为字节码的过程,可以直接利用反编译工具,查看细节。
JVM运行时的优化:通常是编译器和解释器共同作用的结果。
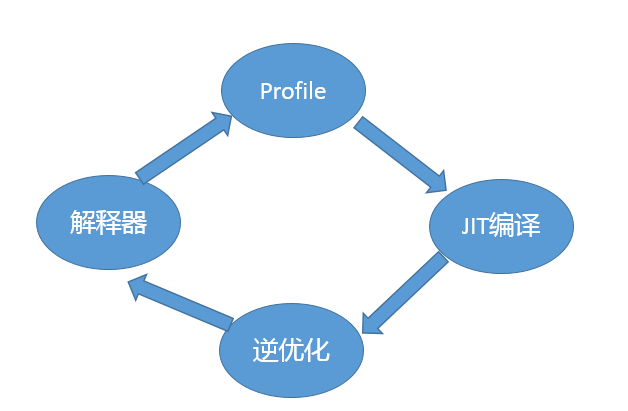
解释器和编译器会进行一些通用的优化。例如锁优化和Intrinsic 机制。
即时编译器:通过对方法调用的计数统计,甄别出热点代码,编译为本地点吗。另一个优化场景,则是针对热点循环代码,利用栈上替换技术。JIT可以看作基于两个计数器实现,方法计数器和回边计数器提供给JVM 统计数据,以定位到热点代码。
勘查优化
- 编译器查看
-XX:+PrintCompilation 打印编译的细节
XX:UnlockDiagnosticVMOptions -XX:+LogCompilation -XX:LogFile= 输出更多的编译细节
-XX:+PrintInlining 打印内联的发生
- 代码缓存
可以利用 JMC、JConsole 等查看具体的统计信息。
- 调整热点代码门限值
利用CompileThreshold 调整JIT的默认门限,利用UseCounterDecay关闭计数器衰减。
- 调整Code Cache 大小
利用XX:ReservedCodeCacheSize调整Code Cache的大小,可以调整初始化大小-XX:InitialCodeCacheSize
- 调整编译器线程数,或者选择适当的编译器模式
client模式只会有一个编译线程。而server模式是默认两个,C1和C2,会根据CPU内核数目计算C1 和 C2 的数值。
增强的多处理器中,增大编译线程数,可能会充分利用CPU资源,但是当系统繁忙时,反而会导致线程争抢过多资源。
- 其他的优化
减少进入安全点。
在 JIT 过程中,逆优化等场景需要插入安全点。
常规的锁优化解决。利用-XX:-UseBiasedLocking 关闭偏向锁。